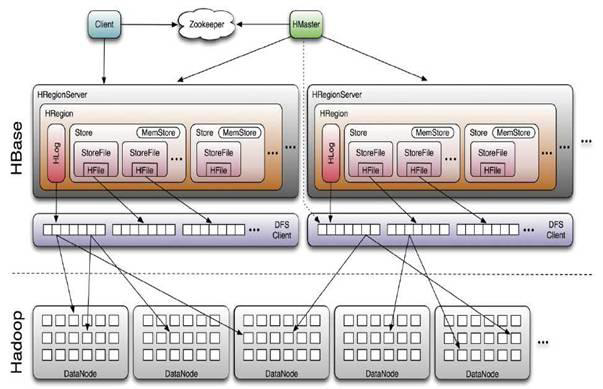
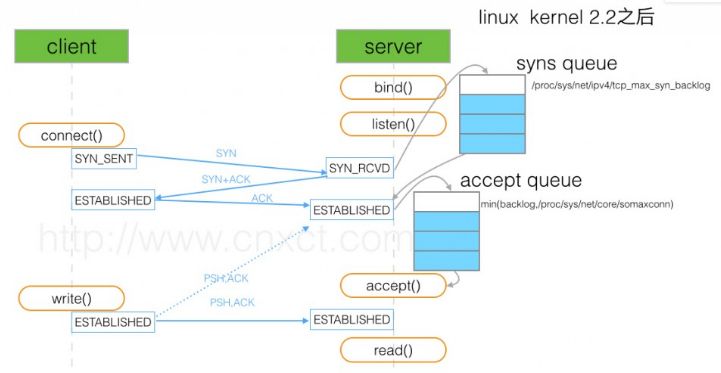
RPC概述
参考文章
RPC组成
Hadoop RPC主要由三大类组成,即RPC、Client、和Server ,分别对应对外编程接口、客户端实现和服务器端实现。Hadoop 关于rpc的代码在hadoop-common下的org.apache.hadoop.ipc包中。
类结构关系详解
类图是老版本的,部分函数名有变化但是架构没变。
ipc.RPC
关键类图如下:

ipc.Client
关键类图分析如下:

ipc.Server

源码分析
client 实现
Client端实现结构如下图所示,从图中可以看出Client 包含两个内部类 Call和Connection

static class Call 内部类
该类封装了一个RPC请求,它包含五个成员变量,分别是唯一标识id,函数调用信息rpcRequest、函数执行返回值rpcResponse,异常信息error和执行完成标识done。由于HadoopRPCServer采用了异步方式处理客户端请求,这使得远程过程调用的发生顺序与结果返回顺序无直接关系,而Client端正是通过id识别不同的函数调用。当客户端向服务端发送请求时,只需要填充id和rpcRequest这两个变量,而剩下的三个变量:rpcResponse,error,done,则由服务端根据函数执行情况填充.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19static class Call {
final int id; // call id
final int retry; // retry count
final Writable rpcRequest; // the serialized rpc request
Writable rpcResponse; // null if rpc has error
IOException error; // exception, null if success
final RPC.RpcKind rpcKind; // Rpc EngineKind
boolean done; // true when call is done
...
public synchronized void setRpcResponse(Writable rpcResponse) {
this.rpcResponse = rpcResponse;
callComplete();
}
...
protected synchronized void callComplete() {
this.done = true;
notify(); // notify caller
}
}通过Call的setRpcResponse来设置RPC请求返回的结果,设置后并调用Call的callComplete方法
private class Connection extends Thread内部类
用Client与每个Server之间维护一个通信连接。该连接相关的基本信息及操作被封装到Connection类中,其中基本信息主要包括:通信连接唯一标识remoteId,与Server端通信的Socket,网络输入流in,网络输出流out,保存RPC请求的哈希表calls等.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47private class Connection extends Thread {
private InetSocketAddress server; // server ip:port
private final ConnectionId remoteId; // connection id
private Socket socket = null; // connected socket
private DataInputStream in;
private DataOutputStream out;
...
private Hashtable<Integer, Call> calls = new Hashtable<Integer, Call>();
...
private synchronized void setupIOstreams(
AtomicBoolean fallbackToSimpleAuth)
{
if (socket != null || shouldCloseConnection.get()) {
return;
}
try {
if (LOG.isDebugEnabled()) {
LOG.debug("Connecting to "+server);
}
if (Trace.isTracing()) {
Trace.addTimelineAnnotation("IPC client connecting to " + server);
}
short numRetries = 0;
Random rand = null;
while (true) {
// 与远程服务器建立连接, 创建一个Socket对象
setupConnection();
InputStream inStream = NetUtils.getInputStream(socket);// 获取输入流
OutputStream outStream = NetUtils.getOutputStream(socket); // 获取输出流
// 发送RPC Header信息给RPC服务器, 这里RPC服务器正常接收后不会响应, 因为只会验证客户端和服务端RPC程序版本是否匹配, 但是验证没通过后会响应失败状态, 并且服务端会关闭连接
writeConnectionHeader(outStream);
...
// 包装输入输出流给in 和 out
this.in = new DataInputStream(new BufferedInputStream(inStream));
if (!(outStream instanceof BufferedOutputStream)) {
outStream = new BufferedOutputStream(outStream);
}
this.out = new DataOutputStream(outStream);
// 调用start()启动线程
start();
return;
}
}
}
...
}在Connection的setupIOstreams方法中会去建立和服务端的连接,本质会去创建一个Socket对象,建立一个TCP长连接,并且封装相关输入输出流。最后调用start()启动线程
1 | public void sendRpcRequest(final Call call) |
客户端发起RPC请求时,会先去把请求相关的调用方法参数等序列化成字节流发送给服务端,核心代码如上
1 | public void run() { |
connection类的run函数不停地调用receiveRpcResponse()方法来获取服务端结果
receiveResponse 函数的关键代码如下,在receiveResponse中主要获取应答头部,根据服务端返回的头部信息判断Rpc请求应答的status,并读取callId通过callId映射到Call对象,并从该Connection持有的所有的calls映射中删除该call,读取输入流,调用Call对象的setRpcResponse()为该call设置RpcResponse
1 | private void receiveRpcResponse() { |
Client 主类
call()方法:通过ConnectionId获取/建立连接,并封装rpc请求call,通过connection发送rpc请求,发送后同步call代码段中不停地检测call是否done,如果非done则wait()阻塞直到相应的connection调用receiveRpcResponse()方法触发call.setRpcResponse(value)进而触发callComplete()方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43public Writable call(RPC.RpcKind rpcKind, Writable rpcRequest,
ConnectionId remoteId, int serviceClass,
AtomicBoolean fallbackToSimpleAuth) throws IOException {
final Call call = createCall(rpcKind, rpcRequest);
Connection connection = getConnection(remoteId, call, serviceClass,
fallbackToSimpleAuth);
try {
connection.sendRpcRequest(call); // send the rpc request
} catch (RejectedExecutionException e) {
throw new IOException("connection has been closed", e);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
LOG.warn("interrupted waiting to send rpc request to server", e);
throw new IOException(e);
}
synchronized (call) {
while (!call.done) {
try {
call.wait(); // wait for the result
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
throw new InterruptedIOException("Call interrupted");
}
}
if (call.error != null) {
if (call.error instanceof RemoteException) {
call.error.fillInStackTrace();
throw call.error;
} else { // local exception
InetSocketAddress address = connection.getRemoteAddress();
throw NetUtils.wrapException(address.getHostName(),
address.getPort(),
NetUtils.getHostname(),
0,
call.error);
}
} else {
return call.getRpcResponse();
}
}
}getConnection()方法:
首先通过ConnectionID查找client的connections中是否包含改connection, 不包含则创建新的并加入到connections中。调用Connection的setupIOstreams方法包装输入、输出流并调用start().s
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29private Connection getConnection(ConnectionId remoteId,
Call call, int serviceClass, AtomicBoolean fallbackToSimpleAuth)
throws IOException {
if (!running.get()) {
// the client is stopped
throw new IOException("The client is stopped");
}
Connection connection;
/* we could avoid this allocation for each RPC by having a
* connectionsId object and with set() method. We need to manage the
* refs for keys in HashMap properly. For now its ok.
*/
do {
synchronized (connections) {
connection = connections.get(remoteId);
if (connection == null) {
connection = new Connection(remoteId, serviceClass);
connections.put(remoteId, connection);
}
}
} while (!connection.addCall(call));
//we don't invoke the method below inside "synchronized (connections)"
//block above. The reason for that is if the server happens to be slow,
//it will take longer to establish a connection and that will slow the
//entire system down.
connection.setupIOstreams(fallbackToSimpleAuth);
return connection;
}
综上所述,Client端处理流程具体序列如下图所示:

Server 实现
Server的结构如下图所示,从图中可以看出,server端包含的内部类比较多,其中一些是和Client端重复的Call,还有一些是Server独有的如Reader(Listener的内部类)、Handler、Listener、Responder 他们的作用如下:
- Listener : 请求监听类,用于监听客户端发来的请求.
- Connection :连接类,真正的客户端请求读取逻辑在这个类中.
- Reader : (Listener的内部类)当监听器监听到用户请求,便让Reader读取用户请求数据.
- Call :用于封装客户端发来的请求.
- Handler :请求处理类,会循环阻塞读取callQueue中的call对象,并对其进行操作.
- Responder :响应RPC请求类,请求处理完毕,由Responder发送给请求客户端.

请求处理阶段
该阶段的主要任务是接收来自各个客户端的RPC请求,并将它们封装成固定的格式(Call对象)放到一个共享阻塞队列callQueue中,以便进行后续处理。该阶段内部又分为两个子阶段:请求接收和请求读取,分别有两种线程完成:Listener和Reader请求接收线程Listener初始化源码如下,整个Server只有一个Listener线程,统一负责监听来自客户端的连接请求,一旦有新的请求到达,它会采用轮训的方式从线程池中选择一个Reader线程进行处理。Listener的run() 方法中会阻塞等待客户端请求建立连接,Listener的run()方法的核心代码.
1
2
3
4
5
6
7
8
9private class Listener extends Thread {
private ServerSocketChannel acceptChannel = null; //the accept channel
private Selector selector = null; //the selector that we use for the server
private Reader[] readers = null;
private int currentReader = 0;
private InetSocketAddress address; //the address we bind at
...
}Listerner 的run方法: 在Selector中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35public void run() {
LOG.info(Thread.currentThread().getName() + ": starting");
SERVER.set(Server.this);
connectionManager.startIdleScan();
while (running) {
SelectionKey key = null;
try {
getSelector().select();// 如果Selector中注册的ServerSocketChannel没有新的Socket请求的话, 就阻塞在这里
Iterator<SelectionKey> iter = getSelector().selectedKeys().iterator();
while (iter.hasNext()) {
key = iter.next();
iter.remove();
try {
if (key.isValid()) {
if (key.isAcceptable())
doAccept(key);// 处理连接事件
}
} catch (IOException e) {
}
key = null;
}
} catch (OutOfMemoryError e) {
// we can run out of memory if we have too many threads
// log the event and sleep for a minute and give
// some thread(s) a chance to finish
LOG.warn("Out of Memory in server select", e);
closeCurrentConnection(key, e);
connectionManager.closeIdle(true);
try { Thread.sleep(60000); } catch (Exception ie) {}
} catch (Exception e) {
closeCurrentConnection(key, e);
}
}
...
}紧接着具体的请求接收处理是在Listener的doAccept()方法中处理的,获取连接后会往Reader线程中的多路复用器Selector注册连接,Listener的doAccept方法的核心代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23void doAccept(SelectionKey key) throws InterruptedException, IOException, OutOfMemoryError {
ServerSocketChannel server = (ServerSocketChannel) key.channel();// 拿到ServerSocketchannel
SocketChannel channel;// 拿到Socketchannel
while ((channel = server.accept()) != null) { // 非阻塞的拿到SocketChannel
channel.configureBlocking(false);// 把SocketChannel设置为非阻塞模式
channel.socket().setTcpNoDelay(tcpNoDelay);
channel.socket().setKeepAlive(true);
Reader reader = getReader();// 随机轮询获取一个Rearder线程
Connection c = connectionManager.register(channel);
// If the connectionManager can't take it, close the connection.
if (c == null) {
if (channel.isOpen()) {
IOUtils.cleanup(null, channel);
}
connectionManager.droppedConnections.getAndIncrement();
continue;
}
key.attach(c); // so closeCurrentConnection can get the object
reader.addConnection(c);
}
} 客户端和服务端连接建立成功之后,服务端的Reader线程中维护了连接,有了连接就可以传输数据,Reader线程的run方法中就是阻塞去等待客户端的请求数据,一旦该连接上有可读数据,该Reader线程就会被唤醒,紧接着会去解析字节流序列化请求数据,封装成Call对象,塞到callQueue阻塞队列,Reader的run()方法的核心代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39public void run() {
LOG.info("Starting " + Thread.currentThread().getName());
try {
doRunLoop();
} finally {
try {
readSelector.close();
} catch (IOException ioe) {
LOG.error("Error closing read selector in " + Thread.currentThread().getName(), ioe);
}
}
}
private synchronized void doRunLoop() {
while (running) {
SelectionKey key = null;
try {
// consume as many connections as currently queued to avoid
// unbridled acceptance of connections that starves the select
int size = pendingConnections.size();
for (int i=size; i>0; i--) {
Connection conn = pendingConnections.take();
conn.channel.register(readSelector, SelectionKey.OP_READ, conn);
}
readSelector.select();// 如果Selector中注册的SocketChannel中都没有可读数据的话, 就阻塞在这里
Iterator<SelectionKey> iter = readSelector.selectedKeys().iterator();
while (iter.hasNext()) {
key = iter.next();
iter.remove();
try {
if (key.isReadable()) { // SocketChannel有可读数据
doRead(key);
}
...
}
}
}
}
} 在Reader的run 中调用了doRunLoop()方法,该方法将connections注册到readSelector,并调用doRead()读取SockletChannel中的数据(如果有)。doRead()中具体的读取及解析请求数据交给Connection来处理,核心代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17void doRead(SelectionKey key) throws InterruptedException {
int count = 0;
Connection c = (Connection)key.attachment();
if (c == null) {
return;
}
c.setLastContact(Time.now());
try {
count = c.readAndProcess();
} catch (InterruptedException ieo) {
LOG.info(Thread.currentThread().getName() + ": readAndProcess caught InterruptedException", ieo);
throw ieo;
} catch (Exception e) {...
}
}
}在doRead中调用了Connection的readAndProcess()方法,接着来看Connection类的readAndProcess()方法,主要从连接中读取请求数据,核心代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public int readAndProcess()
throws WrappedRpcServerException, IOException, InterruptedException {
while (true) {
...;
if (data == null) {
dataLengthBuffer.flip();
dataLength = dataLengthBuffer.getInt();
checkDataLength(dataLength);
data = ByteBuffer.allocate(dataLength);// 根据dataLength创建一个dataLength大小的缓冲区, 用来读数据
}
count = channelRead(channel, data);// 读取第一次请求Header信息或请求数据
if (data.remaining() == 0) {
dataLengthBuffer.clear();// 清空dataLengthBuffer
data.flip();
boolean isHeaderRead = connectionContextRead;
processOneRpc(data.array());// 处理rpc请求,把封装好的请求信息Call塞到callQueue阻塞队列
data = null;
if (!isHeaderRead) { // 读取第一次RPC请求Header之后会再continue, 继续读取请求数据
continue;
}
}
return count;
}在readAndProcess中调用processOneRpc()方法处理rpc请求,在processOneRpc()中调用processRpcRequest()方法来将请求解析封装成server端的Call对象并加入callQueue中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33private void processOneRpc(byte[] buf)
throws IOException, WrappedRpcServerException, InterruptedException {
int callId = -1;
// 通过输入流读取buf
final DataInputStream dis =
new DataInputStream(new ByteArrayInputStream(buf));
// 通过流操作,获取header
final RpcRequestHeaderProto header =
decodeProtobufFromStream(RpcRequestHeaderProto.newBuilder(), dis);
callId = header.getCallId();
callId = header.getCallId();
retry = header.getRetryCount();
.......;
if (callId < 0) { // callIds typically used during connection setup
processRpcOutOfBandRequest(header, dis);
} else if (!connectionContextRead) {
throw new WrappedRpcServerException(
RpcErrorCodeProto.FATAL_INVALID_RPC_HEADER,
"Connection context not established");
} else {
// callId正常 调用processRpcRequest
processRpcRequest(header, dis);
}
} catch (WrappedRpcServerException wrse) { // inform client of error
Throwable ioe = wrse.getCause();
//构造error call,并调用setupResponse函数通知给客户端错误。
final Call call = new Call(callId, retry, null, this);
setupResponse(authFailedResponse, call,
RpcStatusProto.FATAL, wrse.getRpcErrorCodeProto(), null,
ioe.getClass().getName(), ioe.getMessage());
call.sendResponse();
throw wrse;
}
1 | private void processRpcRequest(RpcRequestHeaderProto header, |
至此请求接收结束。
请求处理
该阶段的主要任务是从共享队列callQueue中获取Call对象,执行相应的函数调用,并将结果返回给客户端,这全部由Handler线程完成的。Server端可同时存在多个Handler线程。它们并行从共享队列中读取Call对象,经执行对应的韩式调用后,将尝试着直接将结果返回给对应的客户端。但考虑到某些函数调用返回的结果很大或者网络速度过慢,可能难以将结果一次性发送到客户端,此时Handler将尝试着将后续发送任务交给Responder线程。Handler的run方法中会阻塞等待callQueue队列中有请求数据,Handler的run()核心代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58public void run() {
LOG.debug(Thread.currentThread().getName() + ": starting");
SERVER.set(Server.this);
ByteArrayOutputStream buf =
new ByteArrayOutputStream(INITIAL_RESP_BUF_SIZE);
while (running) {
TraceScope traceScope = null;
try {
final Call call = callQueue.take(); // pop the queue; maybe blocked here
String errorClass = null;
String error = null;
RpcStatusProto returnStatus = RpcStatusProto.SUCCESS;
RpcErrorCodeProto detailedErr = null;
Writable value = null;
CurCall.set(call);
...;
try {
// Make the call as the user via Subject.doAs, thus associating
// the call with the Subject
if (call.connection.user == null) {
value = call(call.rpcKind, call.connection.protocolName, call.rpcRequest, call.timestamp);
} else {
value =
call.connection.user.doAs
(new PrivilegedExceptionAction<Writable>() {
public Writable run() throws Exception {
// make the call
// 反射调用对应服务,返回结果ObjectWritable, 传入Connection中接口的Class对象, 是在建立连接之后第一次客户端请求带过来的
return call(call.rpcKind, call.connection.protocolName,
call.rpcRequest, call.timestamp);
}
}
);
}catch(Expection e){...}
...;
CurCall.set(null);
synchronized (call.connection.responseQueue) {
// 同一个连接上的多个响应必须在同步下进行
setupResponse(buf, call, returnStatus, detailedErr,
value, errorClass, error);// 生成返回给客户端的数据包,包含(客户端调用ID+状态status+RPC方法返回值),设置到Call对象中
// Discard the large buf and reset it back to smaller size
// to free up heap.
if (buf.size() > maxRespSize) {
LOG.warn("Large response size " + buf.size() + " for call "
+ call.toString());
buf = new ByteArrayOutputStream(INITIAL_RESP_BUF_SIZE);
}
call.sendResponse();
}catch(Exception e){...}
}
}
}服务端拿到调用参数之后,会反射调用对应服务,返回方法返回值
请求响应
每个Handler线程执行完函数调用后,会尝试着将执行结果返回给客户端,但由于特殊情况,比如函数调用返回的结果过大或者网络异常情况,会将发送任务交给Responder线程,Server端仅存在一个Responder线程,它的内部包含一个多路复用器Selector对象,用于监听SelectionKey.OP_WRITE事件,当Handler没能够将结果一次性发送到客户端时,会向该Selector对象注册SelectorKey.OP_WRITE事件,进而由Responder线程采用异步方式继续发送未发送完成的结果,具体的核心代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public void run() {
LOG.info(Thread.currentThread().getName() + ": starting");
SERVER.set(Server.this);
try {
doRunLoop();
} finally {
LOG.info("Stopping " + Thread.currentThread().getName());
try {
writeSelector.close();
} catch (IOException ioe) {
LOG.error("Couldn't close write selector in " + Thread.currentThread().getName(), ioe);
}
}
}看看 doRunLoop函数干什么,从多路复用器Selector对象获取Handler 未发送的结果,调用doAsyncWrite异步写发送。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22private void doRunLoop() {
long lastPurgeTime = 0; // last check for old calls.
while (running) {
try {
waitPending(); // If a channel is being registered, wait.
writeSelector.select(PURGE_INTERVAL);
Iterator<SelectionKey> iter = writeSelector.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
try {
if (key.isWritable()) {
doAsyncWrite(key);
}
} catch (CancelledKeyException cke) {...}
...;
}
}
}
}那再看看doAsyncWrite()内部
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24private void doAsyncWrite(SelectionKey key) throws IOException {
Call call = (Call)key.attachment();
if (call == null) {
return;
}
if (key.channel() != call.connection.channel) {
throw new IOException("doAsyncWrite: bad channel");
}
synchronized(call.connection.responseQueue) {// 同一个连接上的多个响应必须在同步下进行
if (processResponse(call.connection.responseQueue, false)) {
try {
key.interestOps(0);
} catch (CancelledKeyException e) {
/* The Listener/reader might have closed the socket.
* We don't explicitly cancel the key, so not sure if this will
* ever fire.
* This warning could be removed.
*/
LOG.warn("Exception while changing ops : " + e);
}
}
}
}Server 端的状态转移图如下所示: