
Hadoop Day 2
[TOC]
Hadoop集群部署
Hadoop 部署中需要以下几个主要步骤
eclips + hadoop2.6.5 开发环境配置
所需的软件:
eclipse的配置方法参见“Windows下使用Eclipse工具搭建Hadoop2.6.4开发环境”
可能遇到的错误的解决方案
1 | log4j.rootLogger=debug,stdout,R |
Hadoop家族
- Pig
- Zookeeper
- Hbase
- Hive
- Sqoop
- Avro
- Chukwa
- Cassandra

Pig
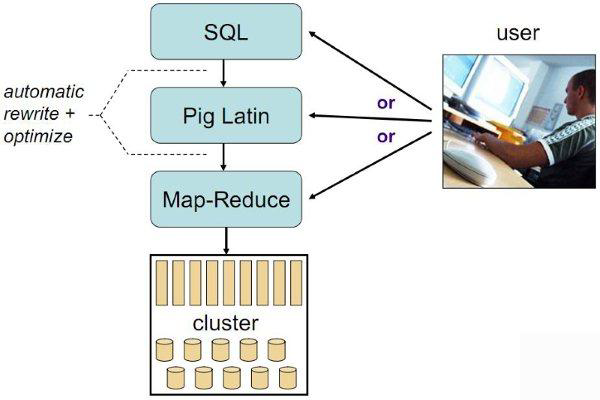
- Hadoop客户端
- 使用类似于SQL的面向数据流的语言Pig Latin
- Pig Latin可以完成排序,过滤,求和,聚组,关联等操作,可以支持自定义函数
- Pig自动把Pig Latin映射为Map-Reduce作业上传到集群运行,减少用户编写Java程序的苦恼
- 三种运行方式:Grunt shell,脚本方式,嵌入式
Hbase
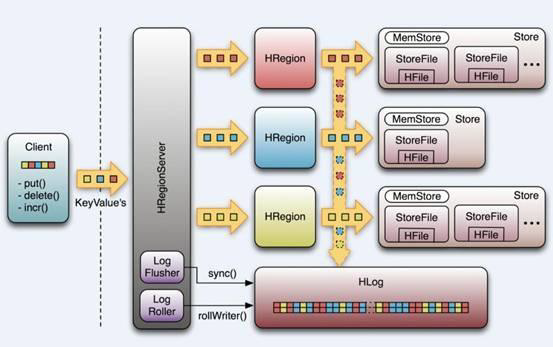
- Google Bigtable的开源实现
- 列式数据库
- 可集群化
- 可以使用shell、web、api等多种方式访问
- 适合高读写(insert)的场景
- HQL查询语言
- NoSQL的典型代表产品
Hive
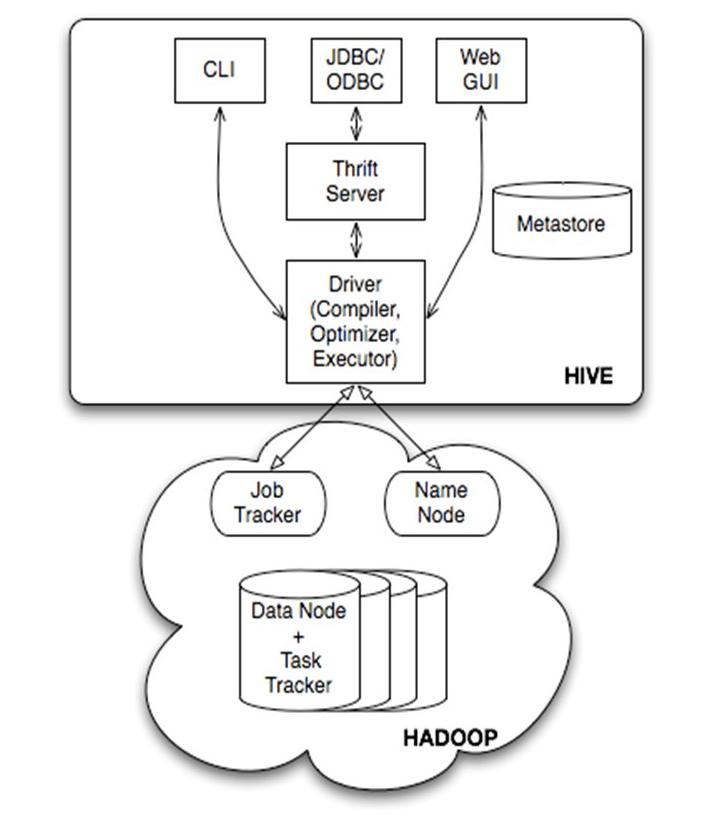
- 数据仓库工具。可以把Hadoop下的原始结构化数据变成Hive中的表
- 数据仓库工具。可以把Hadoop下的原始结构化数据变成Hive中的表
- 支持一种与SQL几乎完全相同的语言HiveQL。除了不支持更新、索引和事务,几乎SQL的其它特征都能支持
- 可以看成是从SQL到Map-Reduce的映射器
- 提供shell、JDBC/ODBC、Thrift、Web等接口
Zookeeper
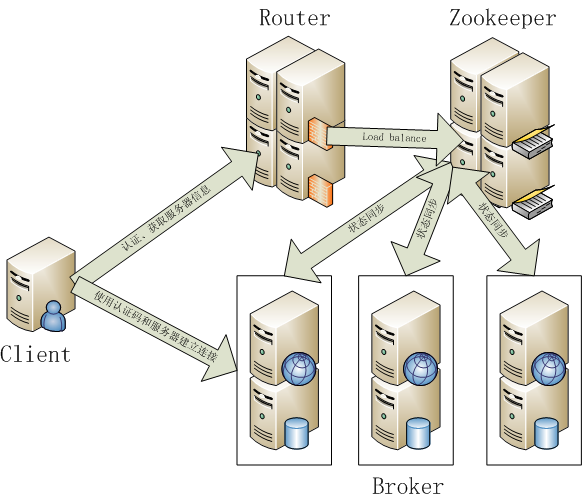
- Google Chubby的开源实现
- 用于协调分布式系统上的各种服务。例如确认消息是否准确到达,防止单点失效,处理负载均衡等
- 应用场景:Hbase,实现Namenode自动切换
- 工作原理:领导者,跟随者以及选举过程
Sqoop
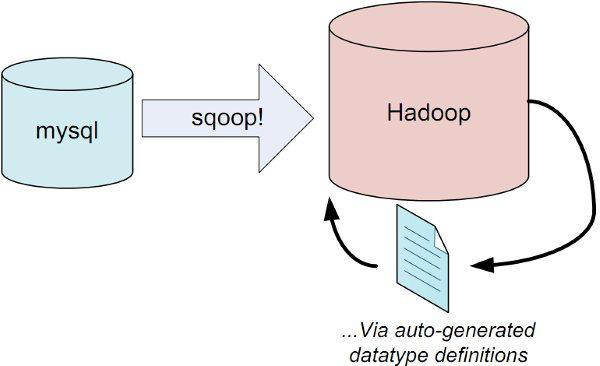
- 用于在Hadoop和关系型数据库之间交换数据
- 通过JDBC接口连入关系型数据库
Avro
- 数据序列化工具,由Hadoop的创始人Doug Cutting主持开发
- 用于支持大批量数据交换的应用。支持二进制序列化方式,可以便捷,快速地处理大量数据
- 动态语言友好,Avro提供的机制使动态语言可以方便地处理 Avro数据。
- Thrift接口
Chukwa
- 架构在Hadoop之上的数据采集与分析框架
- 主要进行日志采集和分析
- 通过安装在收集节点的“代理”采集最原始的日志数据
- 代理将数据发给收集器
- 收集器定时将数据写入Hadoop集群
- 指定定时启动的Map-Reduce作业队数据进行加工处理和分析
- Hadoop基础管理中心(HICC)最终展示数据
Cassandra
- NoSQL,分布式的Key-Value型数据库,由Facebook贡献
- 与Hbase类似,也是借鉴Google Bigtable的思想体系
- 只有顺序写,没有随机写的设计,满足高负荷情形的性能需求
hadoop 实例运行
代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90example 1 word count:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper //继承Mapper类实现map方法
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer //继承并Reducer类并实现reduce方法
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
1 | example 2 :对电话清单进行整理 |